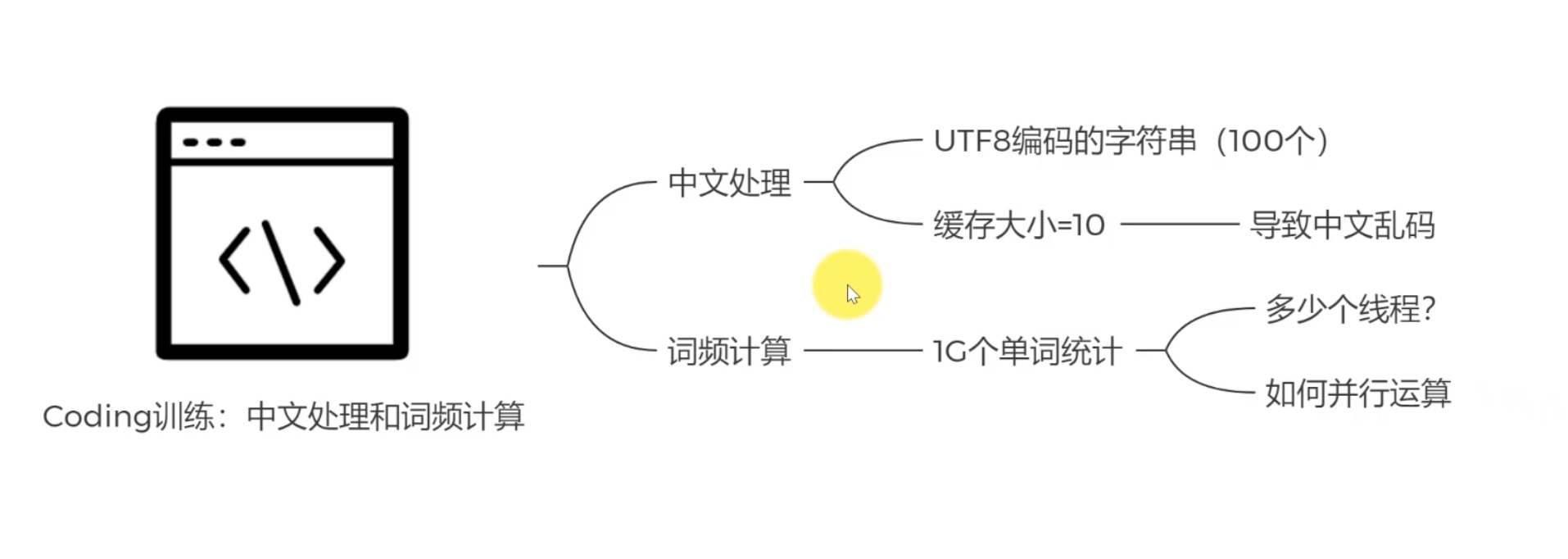
中文乱码处理和词频统计
UTF-8 的编码规则很简单,只有二条:
-
1)对于单字节的符号:字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的;
-
2)对于n字节的符号(n > 1):第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
UTF8编码 与 Unicode编码
GBK是中国标准,只在中国使用,并没有表示大多数其它国家的编码;而各国又陆续推出各自的编码标准,互不兼容,非常不利于全球化发展。于是后来国际组织发行了一个全球统一编码表,把全球各国文字都统一在一个编码标准里,名为Unicode。很多人都很疑惑,到底UTF8与Unicode两者有什么关系?如果要类比的话,UTF8相当于GB2312,Unicode相当于区位码表,不同的是它们之间的编号范围和转换公式。那什么是原始的Unicode编码呢?如果你用过PHP的话,json_encode函数默认会把中文编码成为Unicode,比如“代码笔记A”就会转码成“\u4ee3\u7801\u7b14\u8bb0\u0041”。可以看到每个字都变成了 \uXXXX 的形式,这个就是文字的对应Unicode编码,\u表示Unicode的意思,网上也有用U+表示unicode。现行的Unicode编码标准里,绝大多数程序语言只支持双字节。英文字母、标点也收纳在Unicode编码中。有兴趣的可以在站长工具里尝试“中文转Unicode”,可以得到你输入文字的Unicode编码。
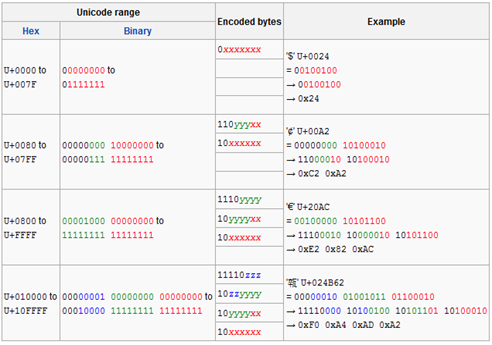
因为英文字符也全部使用双字节,存储成本和流量会大大地增加,所以Unicode编码大多数情况并没有被原始地使用,而是被转换编码成UTF8。下表就是其转换公式:
-
第一种:Unicode从 0x0000 到 0x007F 范围的,是不是有点熟悉?对,其实就是标准ASCII码里面的内容,所以直接去掉前面那个字节 0x00,使用其第二个字节(与ASCII码相同)作为其编码,即为单字节UTF8。
-
第二种:Unicode从 0x0080 到 0x07FF 范围的,转换成双字节UTF8。
-
第三种:Unicode从 0x8000 到 0xFFFF 范围的,转换成三字节UTF8,一般中文都是在这个范围里。
-
第四种:超过双字节的Unicode目前还没有广泛支持,仅见emoji表情在此范围。
中文乱码的那些坑
那么最复杂的其实是utf8,utf8它编码一个中文字符,它用的字节数的个数是不确定的,它可能是两个可能三个。所以我们在编码一段中文的时候,如果我们的缓存大小设置是某一个固定的值比如10(缓存大小),这个时候很有可能我们缓存里面会读出半个中文就,半个汉字那就乱码了,半个汉字能解释成乱码,所以这个问题怎么处理,接下来写一段程序啊教大家去处理。
网上流传着一种错误的方法:
GBK--> UTF-8:
new String( s.getBytes("GBK") , "UTF-8");
如何正确的将GBK转UTF-8 ? (实际上是unicode转UTF-8)
//利用getBytes将unicode字符串转成UTF-8格式的字节数组,然后用utf-8 对这个字节数组解码成新的字符串
new String( s.getBytes("utf-8") , "utf-8");
UTF-8 转GBK原理也是一样
new String( s.getBytes("GBK") , "GBK");=