正则表达式十分钟上手
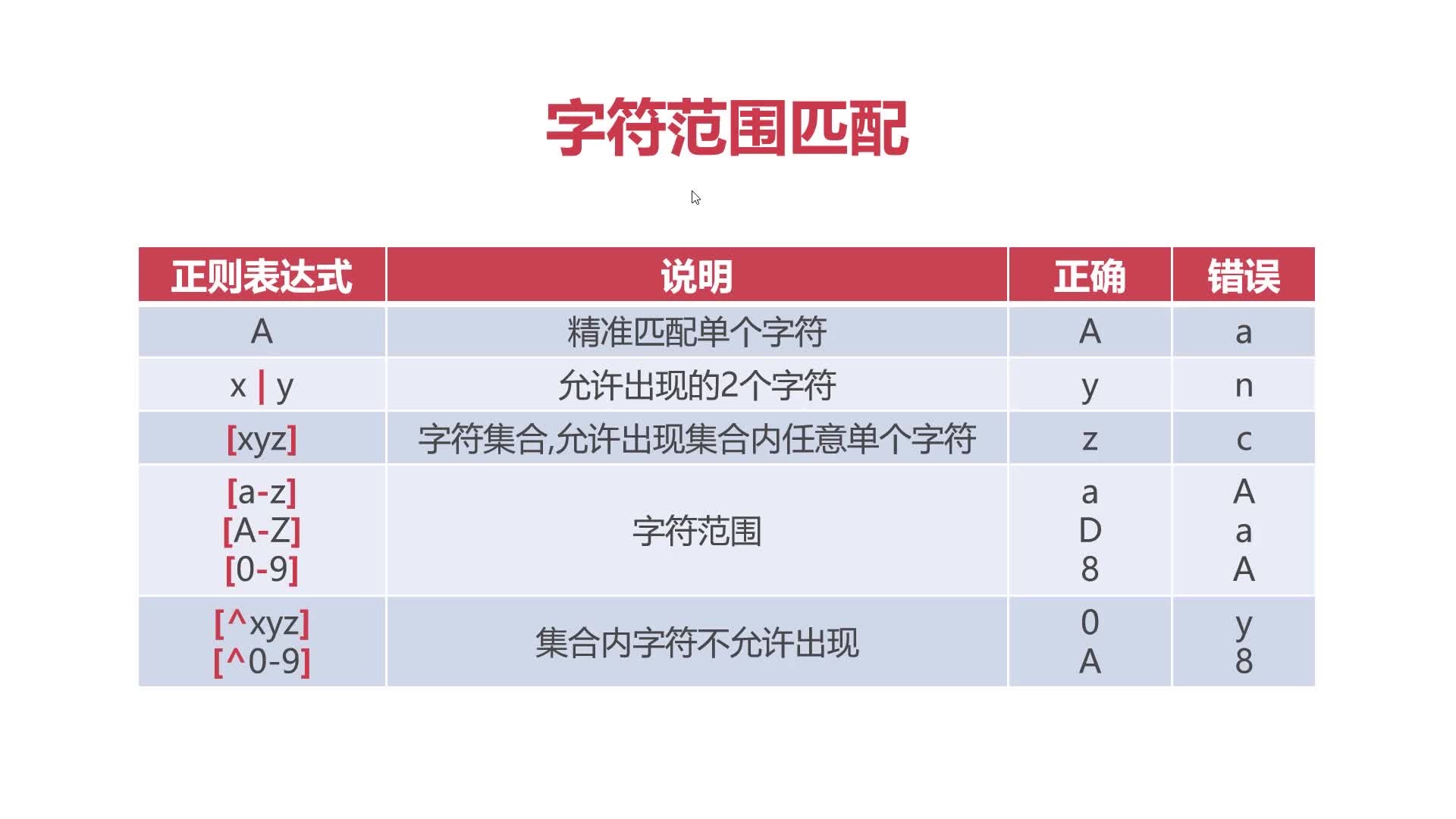
字符范围匹配
A单选x|y多选[a-z]字符集合[^a-z]不包含

精准匹配字符串”hallo”或者”hello”?
h[ae]llo

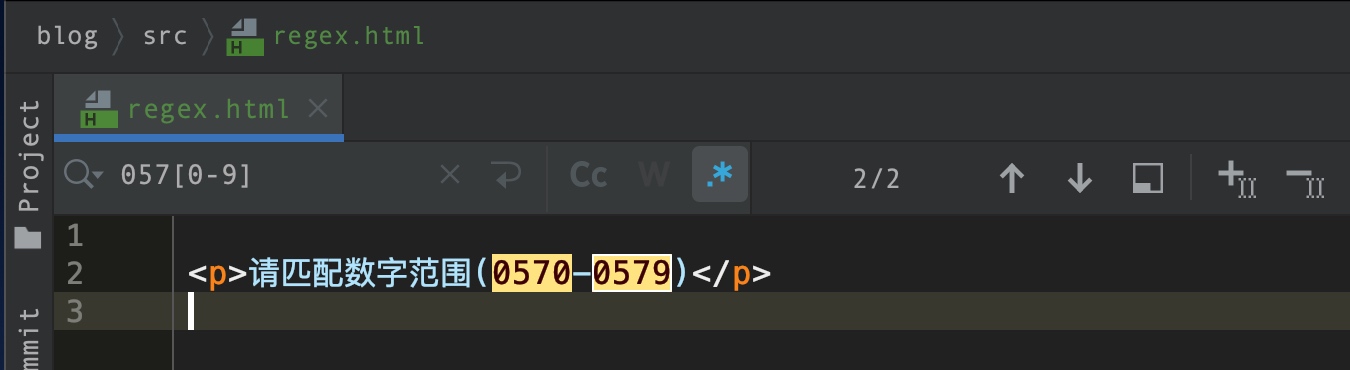
请匹配数字范围(0570-0579)?
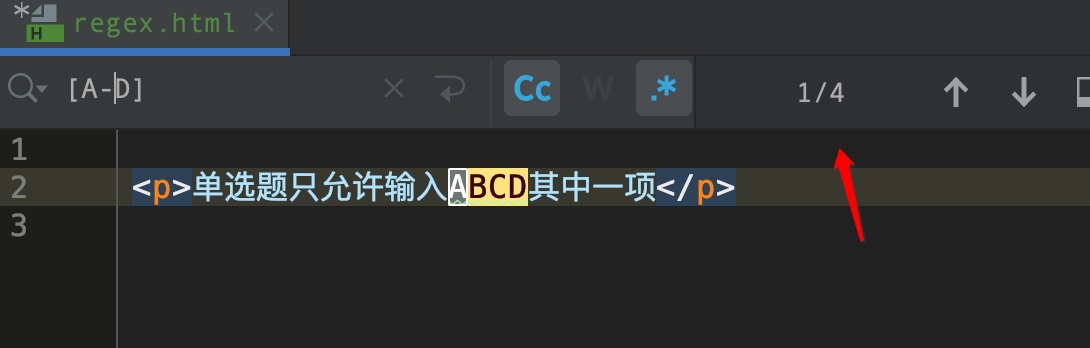
单选题只允许输入ABCD其中一项?
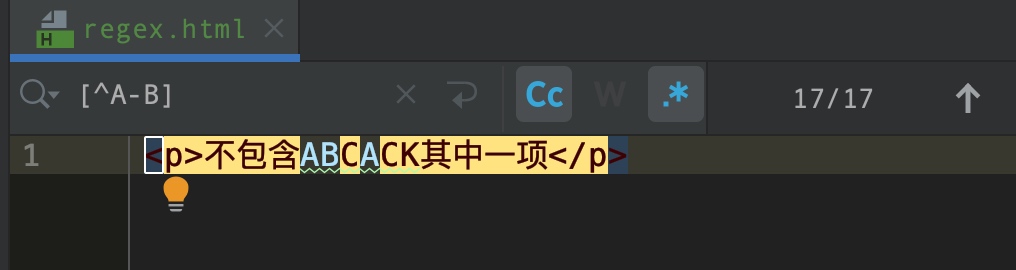
不包含AB字符的项目
剔除文本保留数字
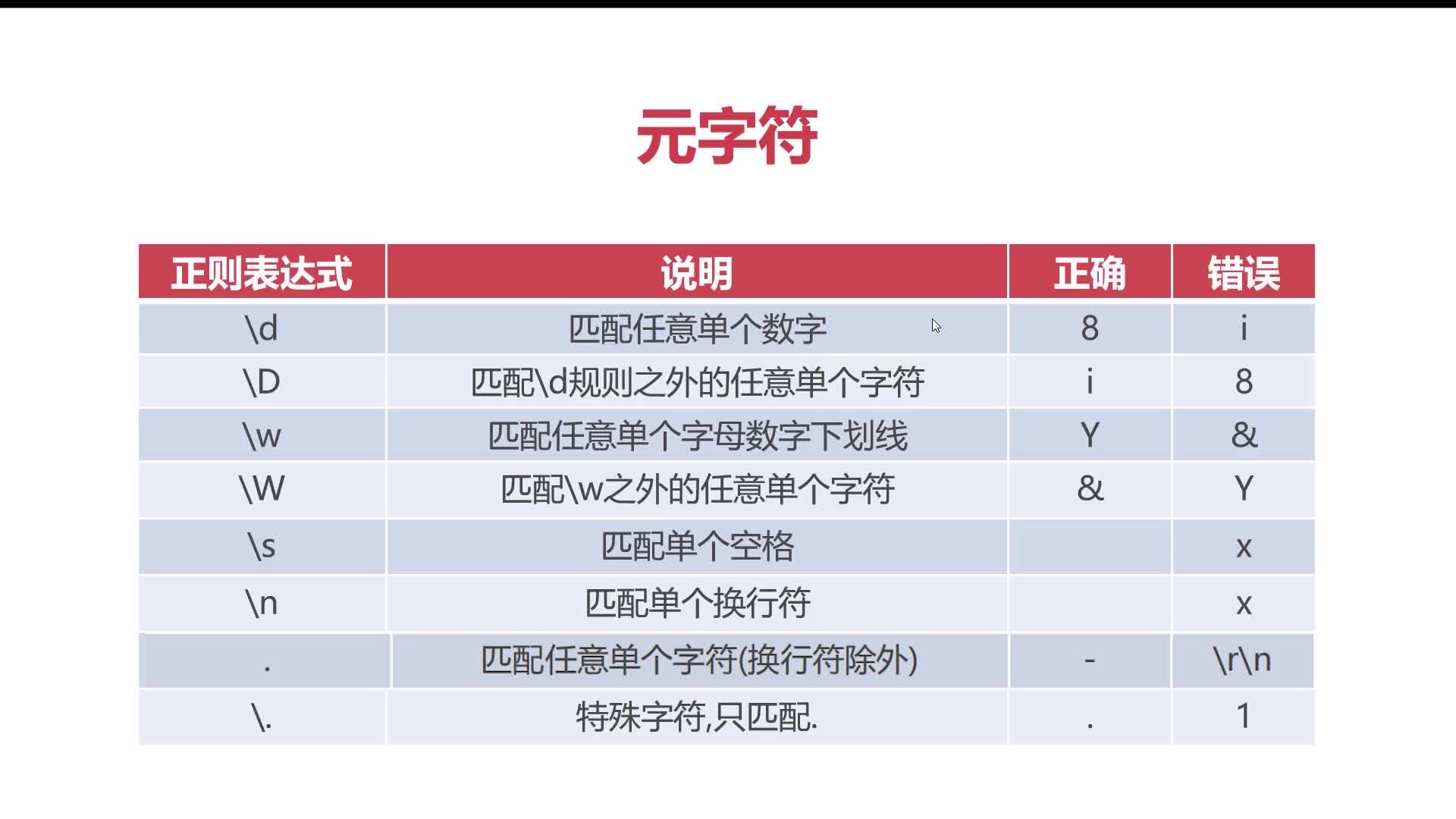
正则表达式元字符
正则表达式中的空格和\s是等价的
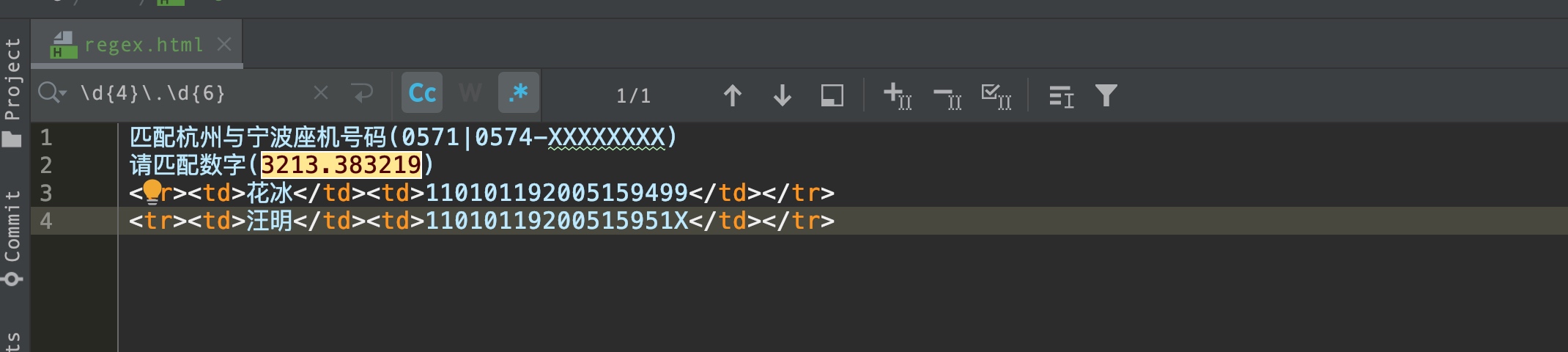
请匹配数字(3213.383219)?
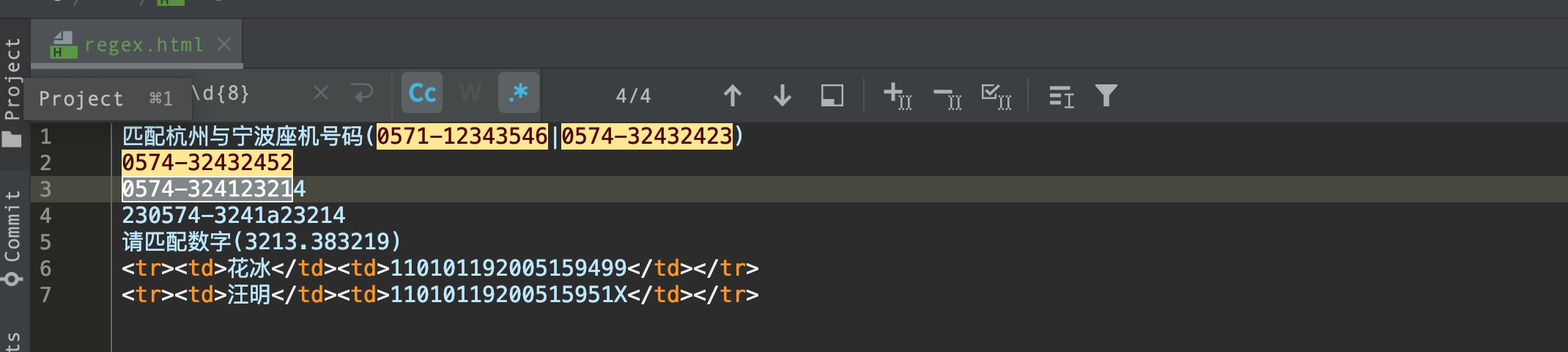
匹配座机号码?
匹配身份证号?

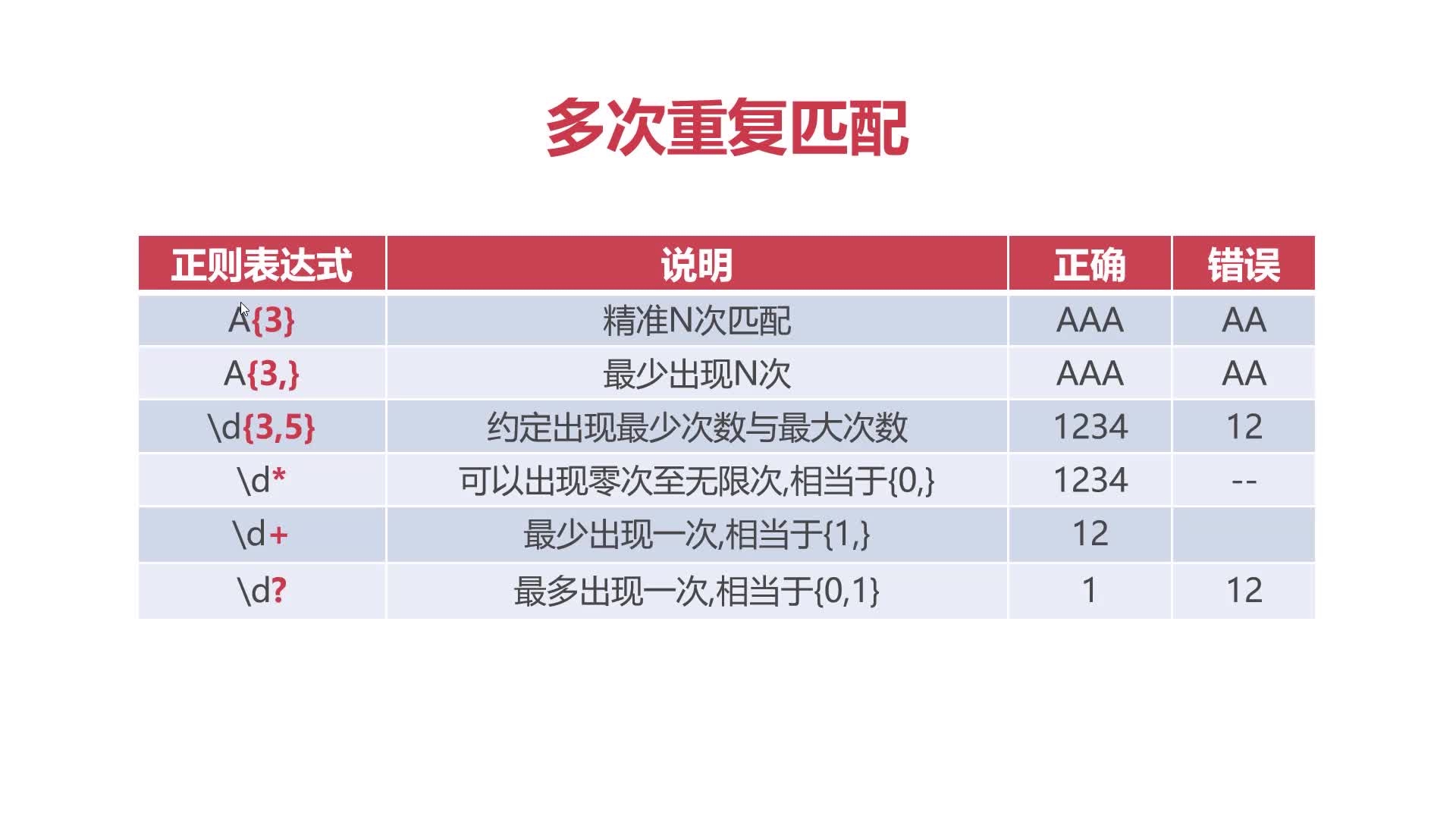
多次重复匹配
验证短信验证码(6位数字) ?

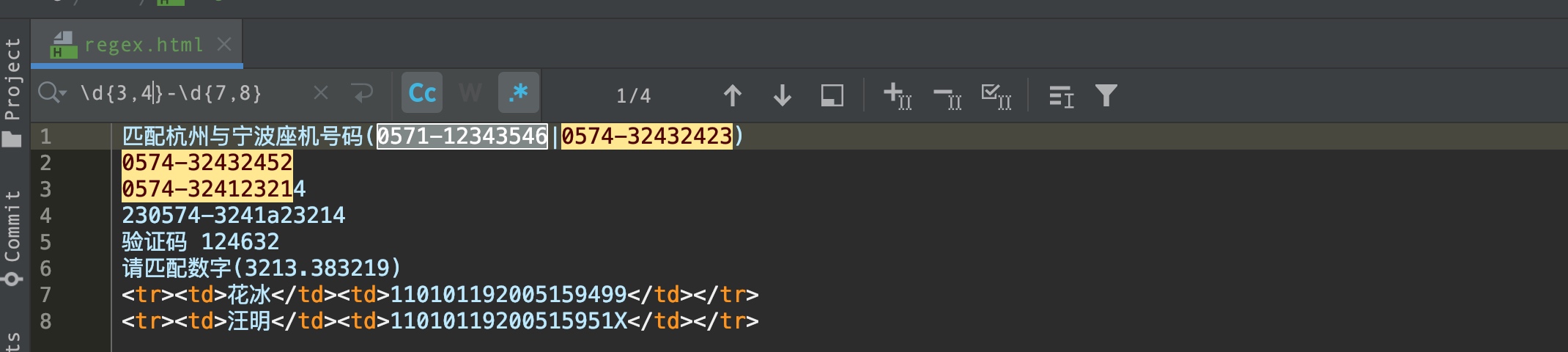
请匹配全国座机号(区号3或4位-电话号码7或8位) ?
请匹配英文姓名(例如:James Watson)?
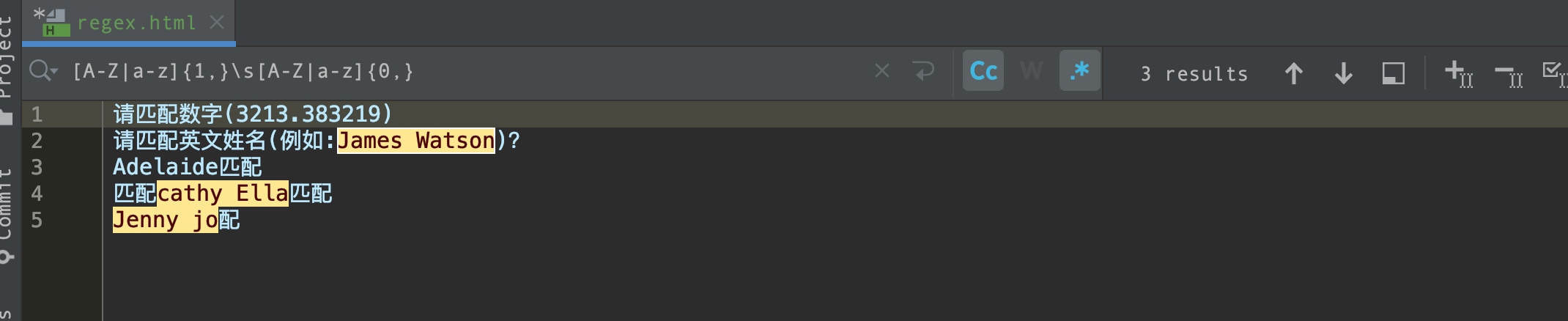
[A-Z|a-z]{1,}\s[A-Z|a-z]{0,}
可简写成
[A-Z|a-z]+\s[A-Z|a-z]*
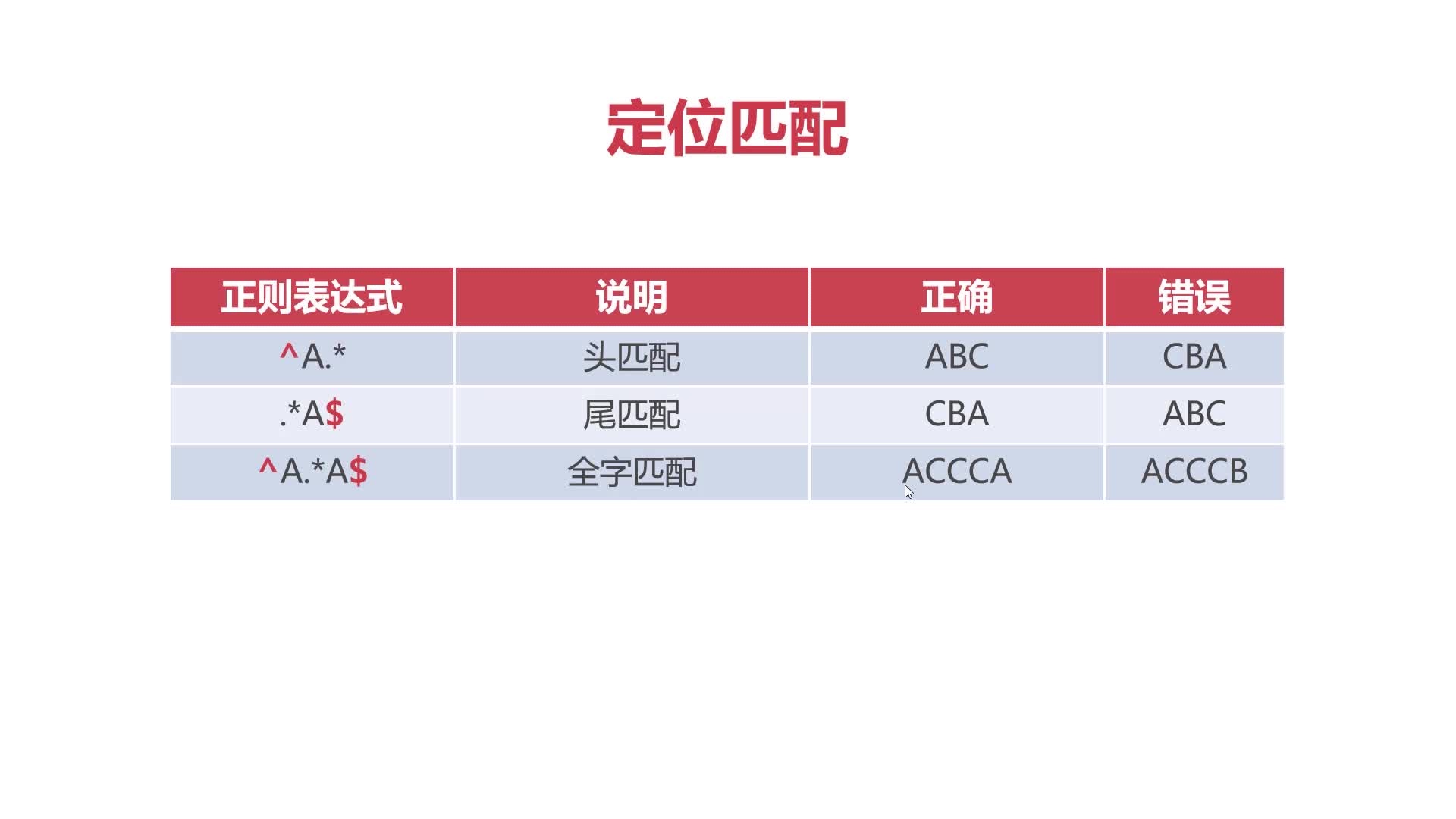
定位匹配
贪婪模式和非贪婪模式
贪婪模式(我们开发时默认的模式就是贪婪模式):
在满足条件的情况下尽可能多匹配到字符串。
比如:正则:\d{6,8},这个正则表达式在匹配时可以匹配6个、7个、8个数字,而如果输入的字符串为111222333,就会匹配8个字符,匹配到的结果为11122233。

非贪婪模式:
在满足条件的情况下尽可能少匹配到字符串。

示例:111222333 正则:\d{6,8}? 匹配结果:111222
注意:表示非贪婪模式的“?”需要写在数量后面
表达式分组:
表达式分组(用小括号)
中文匹配:unicode范围[\u4e00-\u9fa5]

我们一个大表达式进行拆分,它的使用方法是例如原始字符串ababcdcd那么现在我的要求对这个字符串要进行匹配的时候,该怎么做呢?在这里我们就使用了表达式分组,表达式分组它一个典型特点就是用小括号将一个子表达式进行包裹,分组出来的子表达式,它的优先级是最高的,同时也会作为一个整体进行匹配。在以前我们都知道像这种它只能针对于单个字符描述它重复的次数,但是如果增加一个分组以后,那么就可以将分组来进行重复的匹配了。
线正则表达式测试](https://tool.oschina.net/regex/#)